程序員接單網站與軟件外包服務 靈活就業與高效開發的橋梁
隨著數字化轉型的加速,軟件外包服務需求日益增長,程序員接單網站應運而生,成為連接開發者和企業的重要平臺。這些網站不僅為程序員提供了靈活就業的機會,也為中小企業降低了開發成本。以下從平臺類型、優勢、挑戰和選擇建議等方面展開討論。
程序員接單網站主要分為通用型和垂直型兩類。通用平臺如Upwork和Freelancer,覆蓋多種編程語言和項目類型;垂直平臺如Toptal則專注于高端人才,確保高質量交付。這些平臺通常提供項目管理、支付保障和糾紛解決服務,確保交易安全。
軟件外包服務通過接單網站帶來多重優勢。對于程序員來說,它可以實現工作時間和地點的自由,積累多樣化項目經驗;對于企業而言,外包能快速獲取專業技能,縮短開發周期,并降低固定人力成本。例如,一家初創公司可以通過平臺雇傭遠程開發者,以低成本構建MVP(最小可行產品)。
這一模式也面臨挑戰。程序員可能遇到項目付款延遲或需求不明確的問題,而企業則需應對溝通障礙和質量風險。為此,平臺通常引入評級系統、合同模板和托管支付機制來緩解這些風險。
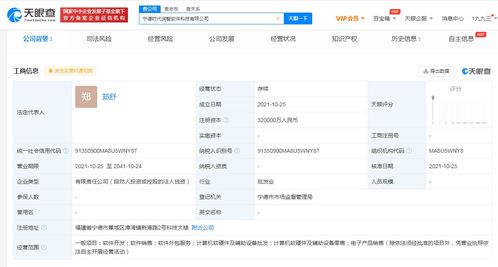
在選擇接單網站時,程序員應關注平臺信譽、費用結構和項目匹配度;企業則需評估開發者資質和過往案例。推薦平臺包括國內的碼市和程序員客棧,以及國際的Fiverr,這些平臺各有側重,用戶可根據需求選擇。
程序員接單網站和軟件外包服務是數字化時代的高效協作方式,通過合理利用,能實現雙贏。未來,隨著AI和遠程工具的普及,這一生態將更加成熟,推動全球軟件開發的創新與增長。
如若轉載,請注明出處:http://www.sxbona.cn/product/11.html
更新時間:2026-01-07 11:41:24